The Education Gateway to the Proto-OKN
Proto-OKN Best Practice Guidelines for Knowledge Graph Construction: Identifiers, Documentation, Axioms, RDF Validation
For questions, contact edugate@proto-okn.net.
Identifiers
Each Theme 1 graph should have its own namespace, and all IRIs should start with your namespace prefix (unless they are reused from another graph). Use a namespace that you own, or use a service such as https://w3id.org/.
Do not use the relative-path feature of URIs, as this makes your URIs ambiguous if used by others (see https://www.w3.org/Addressing/URL/4_3_Partial.html). Your data is easier to reuse if your identifiers do not need context to disambiguate.
It improves interoperability to reuse IRIs from a well-known graph/ontology instead of creating new ones. If there is a type of entity you use for which high-quality vocabularies exist (e.g. chemical compounds), and another Theme 1 graph is dealing with the same kind of entities, please reach out to that team and try to agree on which vocabulary to draw from. You can also reach out to other teams (including Theme 2 / 3 teams) to ask what identifiers others are using.
If you have a good reason to create new IRIs for a domain with a high-quality vocabulary, or it is too late now to reuse IRIs, it is still helpful to refer to the existing vocabulary. You can create a ‘mapping’ using a property like owl:sameAs. Wikidata is a good source of IRIs to map to, for domains that do not have good special-purpose vocabularies. It is not the most systematic, but it is widely used.
Example: http://www.wikidata.org/entity/Q1558 is the Wikidata identifier for Kansas. If you create your own IRI for Kansas, ex:state.kansas, you can assert that they refer to the same thing by putting the triple http://www.wikidata.org/entity/Q1558 owl:sameAs ex:state.kansas . in your graph.
Creating new identifiers
Find a standard format for your identifiers. It can help to have an IRI template for each class, or each combination of a class and a data source, e.g. every River that we extract from data source X will have format Y.
Example ‘format’: “X is a database table with a row for each river, and for each row we use the ‘Name’ (human-readable string) and ‘ID’ (integer) entries, and make an IRI (namespace):geo-feature.river.[Name].source-X-ID.[ID] where Name is converted to lowercase.”
Be aware of what is in your data sources. If you use column X to build identifiers, understand thoroughly what can be in column X. (Is it always a unique value in each row? ‘Name’ values and even ‘ID’ values are often not quite unique. Is it ever null? Will it change in the next version of the source dataset?) The most important considerations for IRI format are uniqueness (accidentally using an identifier twice is worse than having two identifiers for the same thing), and readability (not everything in IRIs will be human-readable, but including the Name along with the ID in the example above doesn’t hurt.)
Documentation
Please document your knowledge graph extensively. Write down whatever you think is relevant to future re-users concerning your data sources, how the graph was extracted from that data, what your classes and properties mean, and what your graph is for. In particular, each team should provide a list of 10-20 competency questions (more is better, depending on the content of your graph). Competency questions are questions in normal English that a human should be able to answer without much effort using query access to your graph. For example, “How many miles of waterway in Hamilton County have been contaminated with PFAS?” Make the questions diverse: each data source you use in your graph should be needed for at least one question, and they should vary in complexity.
Other helpful but optional documentation:
Preferably you would translate your natural-language competency questions into SPARQL (or Cypher, etc.) queries. This practice ensures you have enough properties in your knowledge graph to make its knowledge accessible, and also provides users concrete examples of how to use the graph.
Schema diagram: This is like an entity-relation diagram for a knowledge graph. It has boxes for each class of entities, circles for each type of data literals, and arrows for each property.
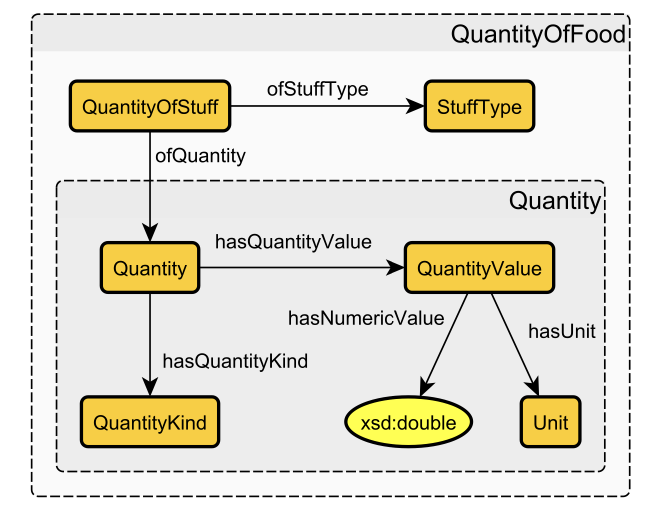 This is a schema diagram just for data involving quantities of food. The diagram for a whole knowledge graph would be similar but larger.
image source
This is a schema diagram just for data involving quantities of food. The diagram for a whole knowledge graph would be similar but larger.
image source
Axioms
Semantics makes a knowledge graph more useful, and a little bit goes a long way. We recommend the following rdfs axioms (if using rdf):
For every class X, include
X rdf:type rdfs:Class .
For every property X, if you can identify a domain A and/or range B for it among your classes, include
X rdfs:domain A .
X rdfs:range B .
For any class A that is a specialization of another class B, include
A rdfs:subClassOf B .
RDF Validation
There are libraries that validate rdf files (check for syntax errors). For example, the RDF I/O technology (RIOT) shell program provided with Apache Jena:
- https://jena.apache.org/documentation/io/
- https://stackoverflow.com/questions/21759243/jena-cli-tool-to-validate-rdf We recommend you use this or a similar program to check your graph files, even if they are automatically generated (e.g. by python rdflib). RIOT does basic syntax validation, but you can also run custom validation for advanced properties using the SHACL constraint language. The PySHACL library
- https://pypi.org/project/pyshacl/ can implement this in Python.
Authors
- Joseph Zalewski
- Email: jzalewski@ksu.edu
- Affiliation: EduGate
- Pascal Hitzler
- Email: hitzler@ksu.edu
- Affiliation: EduGate
- Jim Balhoff
- Email: balhoff@renci.org
- Affiliation: FRINK
- Volkmar Frinken
- Email: volkmar@onai.com
- Affiliation: SPIDER
- Mahir Morshed
- Email: mmorshed@scripps.edu
- Affiliation: FRINK
June 2024
Feel free to reach out with questions any time, preferably to edugate@proto-okn.net.
More guidelines are forthcoming.